Case study · Gladia x Shadow GPU
How Gladia scales its AI inference by 20% at 0 added cost thanks to Shadow GPU
Scaling AI inference often forces a painful trade-off: risk performance bottlenecks or burn cash on over-provisioned GPU clusters. Gladia chose a third path. By challenging the industry obsession with massive hardware and adopting a modular strategy with Shadow GPU, they achieved a 20% surge in platform usage… with zero impact on their infrastructure bill. Dive into the architectural decisions behind this shift, and learn how to turn infrastructure volatility into a competitive advantage.

Platform growth
+20%
20% platform growth with 0% extra cost.
Extra cost
0%
0% extra cost by switching to Shadow's modular GPU strategy.
Time to deploy
Few days
They were able to deploy their first instances and start running services in only a few days.
When your monthly cloud bill becomes the keystone to your sustainability, every GPU decision counts.
For Vincent Varlet, Senior SRE at Gladia, the challenge was fundamental to their long-term viability: power real-time audio transcription, translation, and diarization services for thousands of users, without burning through capital on overpriced GPU capacity. In an industry where inference costs can make or break profitability, Vincent needed a smarter approach to infrastructure economics.
Gladia: tailoring the business model to the realities of high-volume AI inference
Gladia, a European technology firm specializing in audio intelligence, operates in a market where infrastructure expenditure is dominated by a single line item: GPU inference. Vincent's domain encompasses DevOps, SRE and self-hosting foundations. His primary mission is ensuring platform resilience while relentlessly pursuing the GPU solution that offers the best cost-performance ratio.
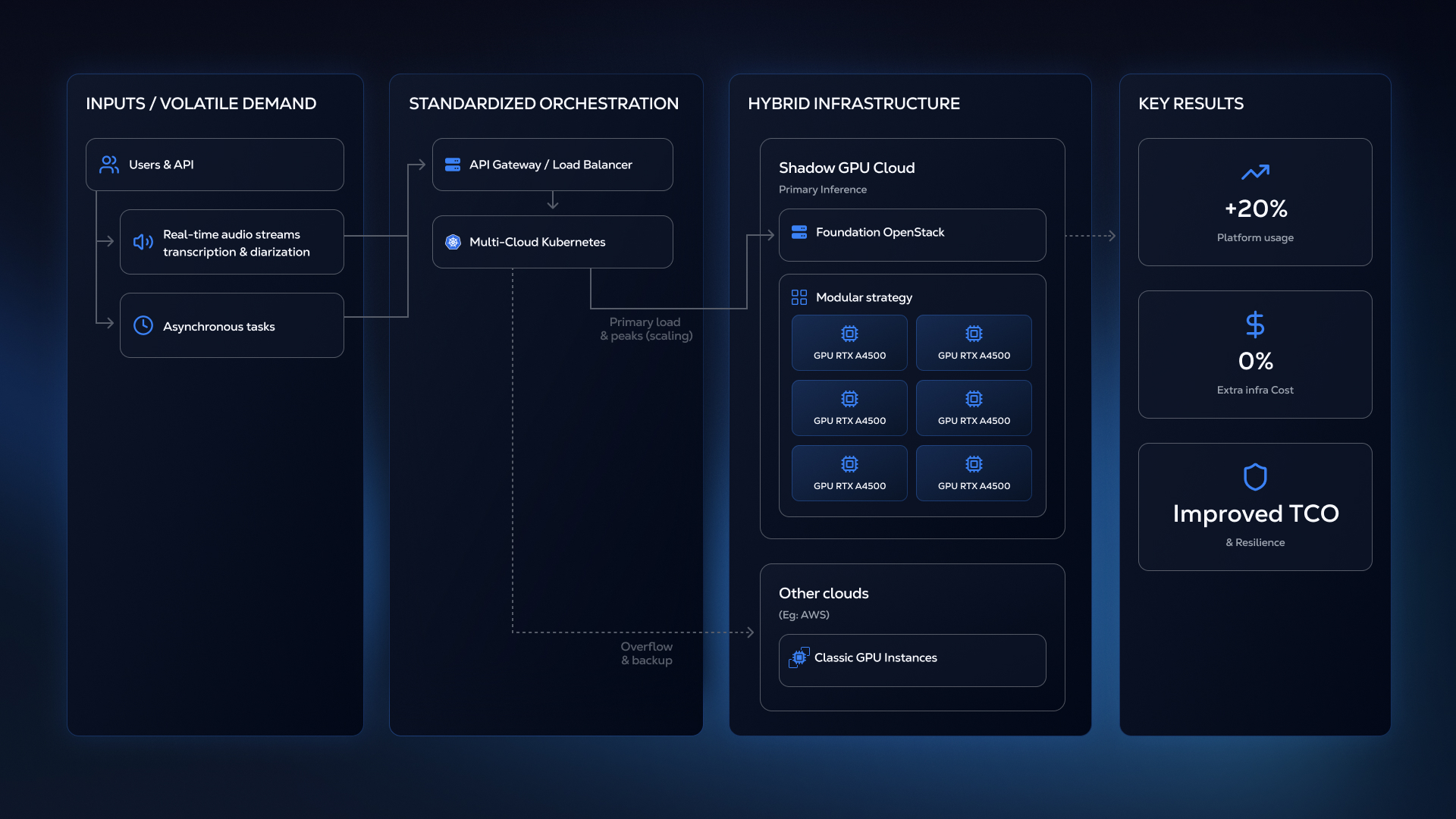
Gladia’s business model creates a unique constraint. The company delivers Speech-To-Text services via both asynchronous processing and streaming transcription with real-time processing that represents their strategic focus. This means GPU capacity must be available instantly during peak business hours, yet the traditional cloud pricing models penalize this volatility mercilessly.
Vincent's team adopted a counterintuitive scaling philosophy: modularity over raw power. Rather than investing in massive, costly GPU units like H100s, which require near-perfect sustained utilization to justify their price, Gladia needed numerous smaller cards that are easier to fill and manage. As Vincent explains, it is strategically better to “fill many small boxes than to try to fill a few large boxes".
In the competitive landscape of AI inference, this architecture simultaneously mitigates operational risk and maximizes profitability. On the operational front, the distributed nature of the hardware ensures resilience: if a smaller unit fails, the workload easily dissipates across the remaining GPUs, which eliminates the need for emergency sourcing. Financially, the path to ROI is also more agile. Leveraging a cluster of accessible, cost-effective cards allows for a lower break-even point compared to capital-intensive high-end hardware, where every idle slot represents a significant drag on investment returns.
But finding a provider who could deliver this modular approach at competitive economics proved challenging.
Why Shadow GPU Cloud fits: realtime audio AI sweet spot
Vincent evaluated Shadow based on three critical factors that had to align simultaneously: GPU economics, capacity availability and technical compatibility.
Shadow’s RTX A4500 GPUs provided the ideal cost-performance ratio for Gladia’s transcription and inference workloads. While they outperform the L4 and sit just slightly below the A10 in speed, they come at a significantly more attractive price. This model empowers businesses to maximize utilization rates while eliminating the financial drain of paying for idle capacity on high-end GPUs. It directly addresses the core requirement of AI inference specialists: securing predictable, cost-effective throughput that is aligned with their actual demand profile.
Also, Shadow's operational dynamics directly supported Gladia's non-linear load profile. Because Gladia requires maximum GPU capacity during business hours, they benefit from Shadow's utilization patterns, gaining access to necessary GPU stock precisely when demand peaks.
On the technical side, Shadow's platform runs on OpenStack, a system Vincent's team already knew well. As a consequence, they were able to deploy their first instances and start running services in only a few days, a timeline that would be unthinkable with major cloud providers requiring extensive retraining. Gladia uses OpenStack instances as the foundation for their standardized Kubernetes cluster, enabling uniform service deployment across multiple cloud environments, including AWS.
Implementation and results
After several months of operating under high-load conditions, the consistent outcomes delivered by Shadow GPU Cloud have fully validated Gladia’s choice. This extended period of intensive activity has proven the solution's reliability, giving the team full confidence to move forward.
The strategic deployment of Shadow’s infrastructure has driven immediate, measurable improvements in Total Cost of Ownership (TCO). Since ramping up capacity, the company has managed a 20% surge in platform utilization while keeping infrastructure costs flat. This concrete financial outcome validated Gladia’s modular strategy : the A4500s provided the capacity and flexibility needed to scale profitably, proving that right-sized GPUs with optimized economics can outperform premium options that appear superior only on paper.
Beyond the financial aspect, the partnership has significantly alleviated the operational burden, guaranteeing access to reactive, high-end support. Collaborating with seasoned SREs who possess a deep understanding of low-level operations has proven to be a game-changer. When operating at the infrastructure layer, responsive, technically competent support isn't a nice-to-have : it's essential for maintaining service reliability. Stability requires active mitigation of intermittent issues rather than passive monitoring, and Shadow’s expertise has become an extension of the team’s own capabilities.
The inference equation: solving for agility, cost, and performance
Gladia's successful deployment with Shadow has validated a broader architectural principle: maintaining a standardized Kubernetes deployment layer across multiple providers creates strategic flexibility. The company can now allocate workloads based on cost, performance, and geographic requirements, adapting quickly as GPU technologies evolve and new capacity options emerge.
As demand for real-time audio intelligence continues growing across European and American markets, this multi-cloud foundation positions Gladia to scale sustainably. The Shadow partnership represents not just a cost optimization, but a proof point for how AI companies can navigate GPU scarcity and pricing volatility without compromising on performance or reliability.
For AI companies specialized in inference, Vincent’s insights offer clarity in a hype-saturated market: " Success implies looking beyond raw power specs to focus on what truly matters: efficiency, modularity and alignment. The goal is to identify partners who deeply understand your actual workload patterns: an area where Shadow has proven its worth.”
About Gladia & Shadow
About Gladia
Gladia is an API-first audio intelligence platform powering real-time transcription, translation, summarization, and speaker diarization for multilingual products. They enable teams to ship live speech features without taking on heavy infrastructure overhead.
About Shadow Cloud
Shadow Cloud delivers GPU infrastructure tuned for AI inference, giving engineering teams flexible access to right-sized NVIDIA GPUs through an OpenStack-based platform with predictable economics.