Étude de cas · Gladia x Shadow GPU
Comment Gladia a accru de 20% sa puissance d'inférence IA sans surcoût grâce à Shadow GPU
Scaler ses capacités d'inférence IA impose souvent un dilemme : risquer de limiter les performances ou brûler son budget sur des clusters GPU surdimensionnés. Gladia a choisi une troisième voie. En adoptant une stratégie modulaire grâce à Shadow GPU, leurs équipes ont pu augmenter leur consommation cloud GPU de +20 %… sans aucun impact sur la facture infrastructure. Plongez dans les choix d'architecture derrière ce virage et découvrez comment transformer la complexité d’une gestion d’infra en avantage compétitif.

Croissance plateforme
+20%
+20 % d'usage sans aucun surcoût.
Surcoût
0%
0 % de surcoût grâce à la stratégie GPU modulaire de Shadow.
Délai de déploiement
Quelques jours
Premières instances déployées et services en production en quelques jours.
Parce que votre facture cloud mensuelle conditionne votre rentabilité, chaque choix de GPU compte.
Pour Vincent Varlet, Senior SRE chez Gladia, c’est un enjeu vital pour la pérennité de l'entreprise : faire fonctionner des services de transcription, traduction et diarisation audio en temps réel pour des milliers d'utilisateurs. Et ce, sans brûler de fonds inutilement dans des serveurs GPU surdimensionnés, sous utilisés et trop chers. Dans un secteur où le coût d'inférence peut faire ou défaire la rentabilité, Vincent devait trouver une approche plus intelligente dans la manière de gérer les coûts de son infrastructure cloud.
Gladia : optimiser son modèle économique face à la réalité de l’inférence IA à grande échelle
Gladia, scale-up européenne spécialisée dans l'intelligence audio, évolue sur un marché où la dépense infra se résume à une ligne : l'inférence GPU. Les missions de Vincent couvre les domaines du DevOps, SRE et le self hosting. Sa mission première est de garantir la résilience de la plateforme tout en identifiant les solutions GPU au meilleur ratio coût/performance.
Le modèle économique de Gladia crée une contrainte singulière. L'entreprise délivre des services de Speech-To-Text à la fois en traitement asynchrone mais également en transcription lors de streaming en temps réel. Des services qui exigent une disponibilité GPU instantanée aux heures de pointe, alors que les modèles tarifaires cloud classiques pénalisent sévèrement cette injonction de rapidité.
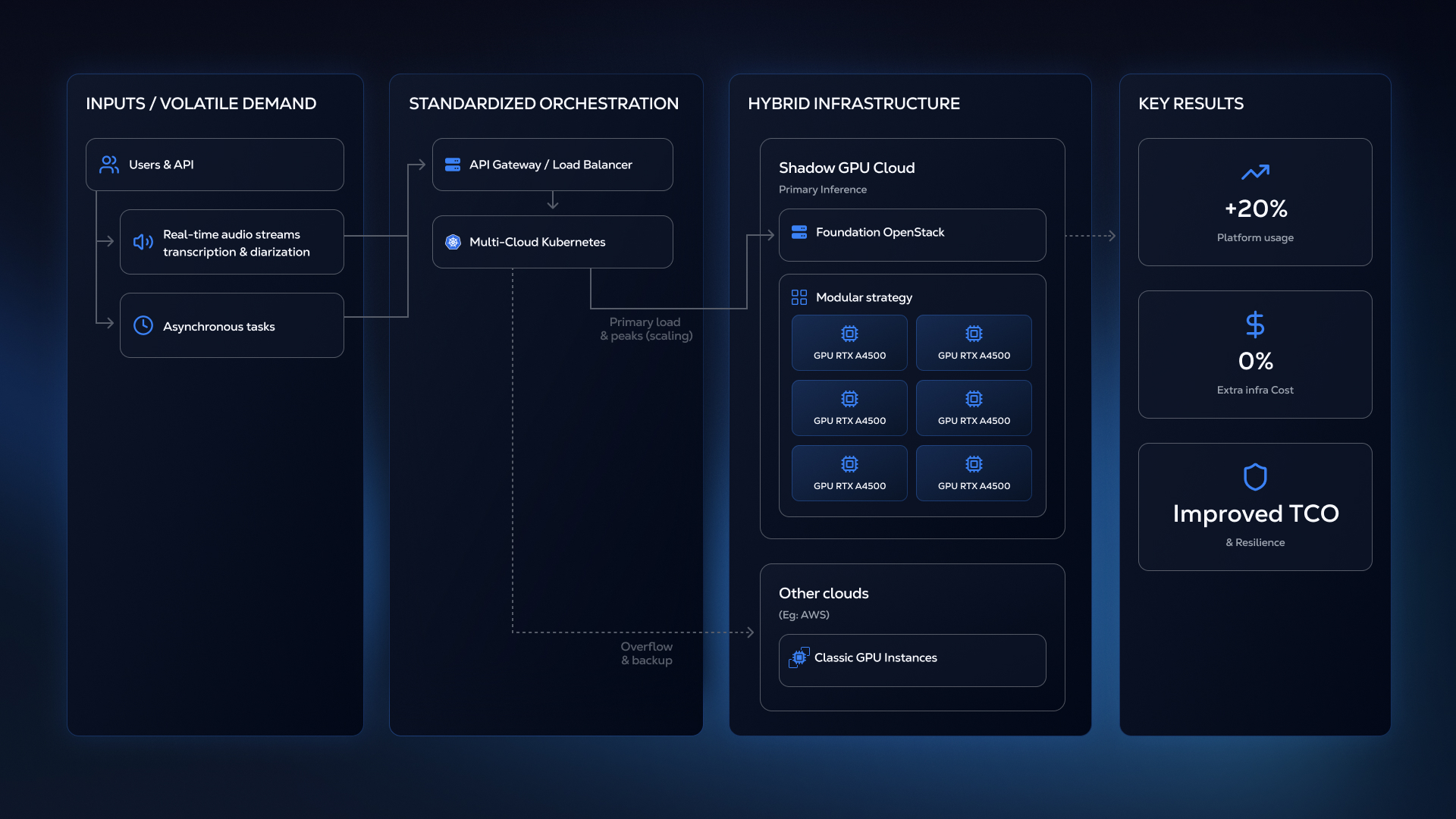
L'équipe de Vincent a adopté une philosophie de scaling à contre-courant : la modularité plutôt que la puissance brute. Au lieu d'investir dans des GPU surdimensionnés et coûteux comme les NVIDIA H100, qui exigent un taux d'utilisation maximum quasi constant pour justifier leur prix élevé, Gladia a opté pour des clusters de GPU moins surpuissants, plus faciles à saturer et à piloter. Comme le résume Vincent, il est stratégiquement plus facile de « remplir plein de petites boîtes plutôt que d'essayer d'en remplir quelques-unes très grosses ».
Dans le paysage concurrentiel de l'inférence IA, cette architecture réduit simultanément le risque opérationnel et maximise la rentabilité. Sur le plan opérationnel, la nature distribuée du hardware garantit la résilience : si une petite unité tombe, la charge se répartit facilement sur les GPU restants, sans avoir recours, en urgence, à du sourcing de nouveau matériel. Financièrement, le chemin vers le ROI est plus évident. Exploiter un cluster de cartes accessibles et économiques abaisse le seuil de rentabilité, contrairement aux GPU haut de gamme, lourds en investissement initial où chaque GPU inutilisé pèse lourd.
Reste à trouver un fournisseur capable de livrer cette approche modulaire avec des economics compétitifs.
Pourquoi Shadow GPU Cloud est le bon choix : le sweet spot de l'audio en temps réel
Vincent a évalué Shadow selon trois facteurs critiques devant s'aligner parfaitement : le prix des GPU, le volume disponible et la compatibilité technique.
Les NVIDIA RTX A4500 20Go de Shadow offrent le ratio coût/performance idéal pour les workloads de transcription et d'inférence de Gladia. Plus performantes que les L4 et proches des A10 en vitesse d'exécution, elles affichent un prix bien plus attractif. Ce modèle permet aux acteurs de l’IA de maximiser le taux d'utilisation des GPU tout en minimisant l’impact financier des ressources inexploitées dans le cas de cartes ultra puissantes comme la H100. Cela répond exactement au besoin des acteurs de l'inférence : sécuriser des ressources sur le long terme qui correspondent à leur besoin économique et stratégique réel.
Côté opérations, la dynamique d'usage de Shadow colle au profil de charge non linéaire de Gladia : la capacité GPU est disponible aux heures business où la demande crête, grâce aux patterns d'utilisation propres à Shadow.
D’un point de vue technique, la plateforme de Shadow fonctionne sur OpenStack, un système déjà maîtrisé par l'équipe de Vincent. Résultat : les premières instances ont été déployées et les services lancés en quelques jours seulement, là où les hyperscalers exigeraient une montée en compétence bien plus longue. Gladia s'appuie sur des instances OpenStack comme socle de base pour ses clusters Kubernetes, garantissant un déploiement homogène des services sur plusieurs environnements cloud, AWS inclus.
Mise en oeuvre et résultats
Après plusieurs mois d'exploitation à pleine charge, la constance des résultats délivrés par Shadow GPU valide pleinement le choix de Gladia. Cette période d'activité intensive a prouvé la fiabilité de la solution, validant la confiance de l’équipe en la plateforme.
Le déploiement stratégique de l'infrastructure Shadow a eu un impact direct et mesurable sur le TCO. Depuis la montée en capacité GPU, l'entreprise a augmenté de +20 % l’usage de sa plateforme tout en gardant des coûts d'infrastructure stables. Ce résultat financier concret valide le choix de la stratégie modulaire de Gladia : les RTX A4500 apportent la capacité et la flexibilité nécessaires pour scaler profitablement, prouvant que des GPU correctement dimensionnés et un modèle économique optimisé sont un meilleur choix que d’investir sur des GPU ultra premiums, trop chers et peu disponibles.
Au-delà de l’aspect financier, le partenariat a fortement allégé la charge opérationnelle de Gladia en sécurisant l’accès à l'expertise d’une équipe support réactive. Collaborer avec des SRE aguerris, capables d'intervenir à bas niveau, change la donne. À ce niveau d'infrastructure, un support humain, réactif et compétent n'est pas un luxe : c'est indispensable pour maintenir un haut niveau de fiabilité. La stabilité exige une mitigation active des incidents intermittents plutôt qu'une simple surveillance, et l'expertise de Shadow prolonge les capacités de l'équipe de Gladia.
L'équation de l'inférence : concilier agilité, coûts et performance
Le déploiement réussi de Gladia avec Shadow GPU confirme un principe d'architecture plus large : maintenir une couche de déploiement Kubernetes standardisée sur plusieurs fournisseurs crée une flexibilité stratégique. L'entreprise peut désormais allouer ses workloads en fonction des coûts, des performances et des besoins géographiques, en s'adaptant vite aux évolutions des GPU et aux nouvelles capacités disponibles.
À mesure que la demande d'intelligence audio temps réel progresse en Europe et aux États-Unis, cette base multi-cloud place Gladia en position de croître durablement. Le partenariat avec Shadow GPU n'est pas qu'une optimisation de coûts : c'est la preuve que les entreprises du secteur de l’IA peuvent prospérer sans être affectées par les pénuries de GPU de GAFAMS et la volatilité des prix, et ce, en alliant performance et fiabilité.
Pour les entreprises IA spécialisées dans l'inférence, la vision de Vincent apporte de la clarté dans un marché à saturation: « Réussir, c'est regarder au-delà des specs brutes pour se concentrer sur l'efficacité, la modularité et l'alignement. L'objectif est d'identifier des partenaires qui comprennent réellement vos contraintes de charge : un domaine où Shadow GPU a fait ses preuves. »
À propos de Gladia & Shadow
À propos de Gladia
Gladia est une plateforme d'intelligence audio API-first qui alimente la transcription, la traduction, le résumé et la diarisation en temps réel pour des produits multilingues. Elle permet aux équipes de livrer des fonctionnalités vocales live sans assumer une lourde dette d'infrastructure.
À propos de Shadow Cloud
Shadow Cloud fournit une infrastructure GPU optimisée pour l'inférence IA, donnant aux équipes d'ingénierie un accès flexible à des GPU NVIDIA justement dimensionnés via une plateforme OpenStack aux économies prévisibles.